
Distillation >> Finetuning
Lot has changed since a year.

Hi Everyone!
It’s been a year since my last post on Adam Smith and a lot has changed since then. I’ve been away due to serious family challenges that deeply affected my mental well-being.
Since then, life has taken quite a turn. I’m now pursuing my master’s degree at Ludwig Maximilian University of Munich, specializing in the mathematics and computer science aspects of machine learning and deep learning.
This past year has been intense learning daily, facing new challenges, and adapting to student life far from home. But as I’ve realized :
You need to let suffering happen to you it builds resilience and agency.
Going forward, I’ll be sharing my learnings from ML/DL, along with insights on technology and the economy, every weekend → A short thoughtful weekend read.
FineTuning : Current Paradigm
The current trend in ML revolves around fine-tuning models, with companies like Thinking Machines (a $12B startup) releasing APIs for accelerated fine-tuning using LoRA (Low-Rank Adaptation) and other methods.
For the non-technical audience → fine-tuning means adapting general-purpose models to specific tasks by updating parts of their parameters.
Example: using a large language model (LLM) and fine-tuning it to become an expert in a specific subject.
But there are several major problem with fine tuning to be honest :
Bound by capacity: If you can only handle 100M parameters, you can’t work with a 1B-parameter model efficiently.
Evaluation is hard: There’s no universal metric; you need extensive testing to validate results often on downstream tasks.
These issues will make it harder in general for a truly accessible super-intelligence since specialized hardware will always remain a barrier.
Enter : Distillation
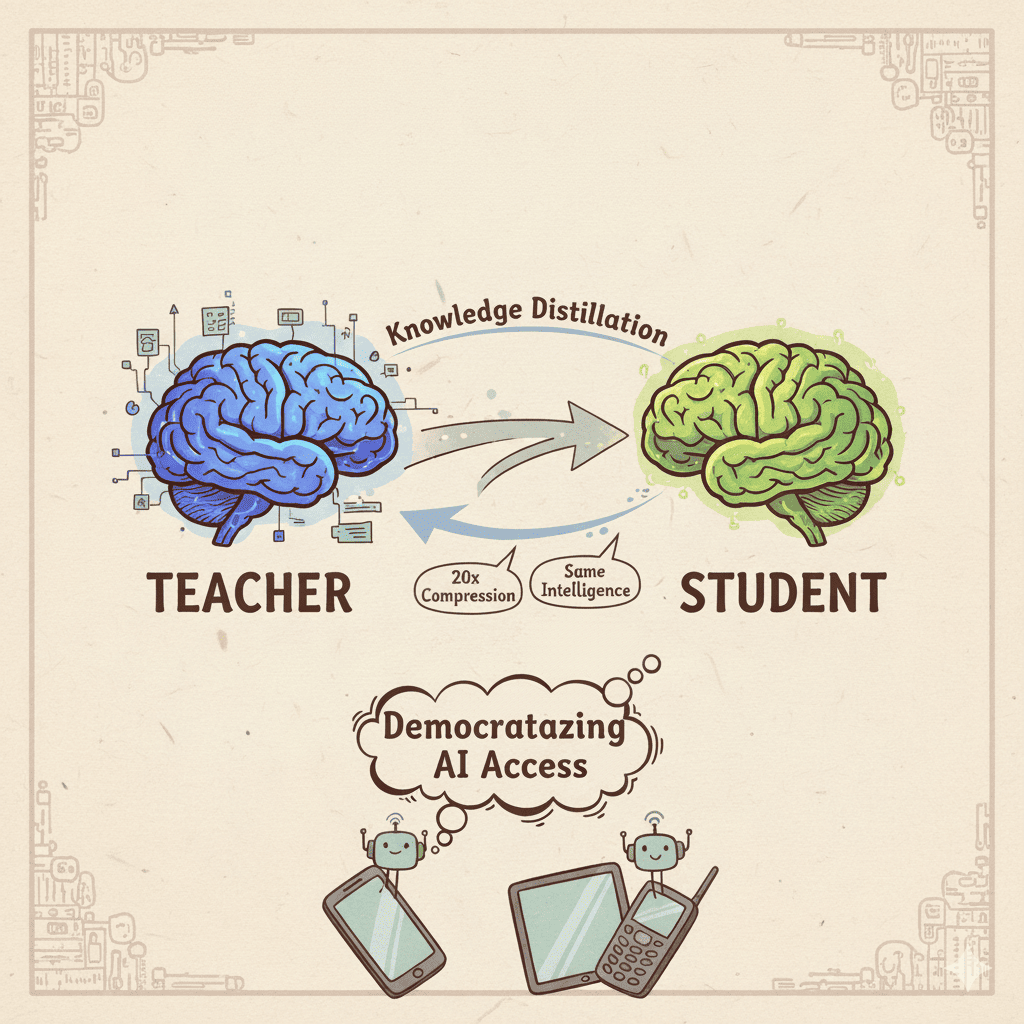
Thankfully, there’s a promising alternative knowledge distillation. It’s still emerging but already showing strong results, with up to 20x compression while maintaining comparable performance with slight degradation.
In simple terms → distillation involves two models:
- Teacher: the large, capable model
- Student: a smaller model learning from the teacher’s behavior
This process allows the smaller model to perform similarly, but with far fewer parameters.
Why distillation could be trending in few years time ? Because it solves the two major problems of fine tuning :
Freedom from capacity limits: You can shrink a 1B-parameter model down to ~50M* while keeping its core abilities. That means the same intelligence, but accessible on smaller, cheaper devices.
Evaluation : You have metrics you can measure about how well the model is performing unlike fine tuning while distillation which helps a lot though this is an active area of research as well.
The compression aspect excites me most as it democratizes access to AI. Imagine the next Alex Krizhevsky experimenting on a phone instead of a supercomputer. Though distillation is a active area of research, a few drawback which I think are there are :
Distillation does require deeper technical understanding as you’re working with loss functions and two-model interactions, but the field is stabilizing fast, with clear winning approaches emerging with standardizations following suit.
If you want to know more about knowledge distillation, this paper is a good starting point : https://arxiv.org/abs/2503.12067 and you can always reach out to me as well.
PS: I’m currently working on distilling language-specific models for 22 Indian languages, aiming to make them run even on low-end or feature phones. We recently distilled a 270M model into 33M parameters about 8x smaller and 10x faster.